
Daten als Grundlage von KI-Projekten – Teil 2
Einen ersten Überblick, wie Big-Data- und KI-Projekte im Unternehmenskontext angestoßen und umgesetzt werden können und sich die Datenkompetenz der Mitarbeiter Schritt für Schritt steigern lässt, liefert ein etabliertes Konzept: das sogenannte CRISP-DM-Phasenmodell.
CRISP-DM steht für Cross Industry Standard Process for Data Mining1 und ist eine von der EU geförderte Methodik, die bereits 1996 als branchenübergreifendes Standardmodell für Data-Mining formuliert wurde. Dieser Prozess ist für erste KI-Projekte sehr empfehlenswert und wird bereits seit vielen Jahren erfolgreich in der Praxis angewandt.
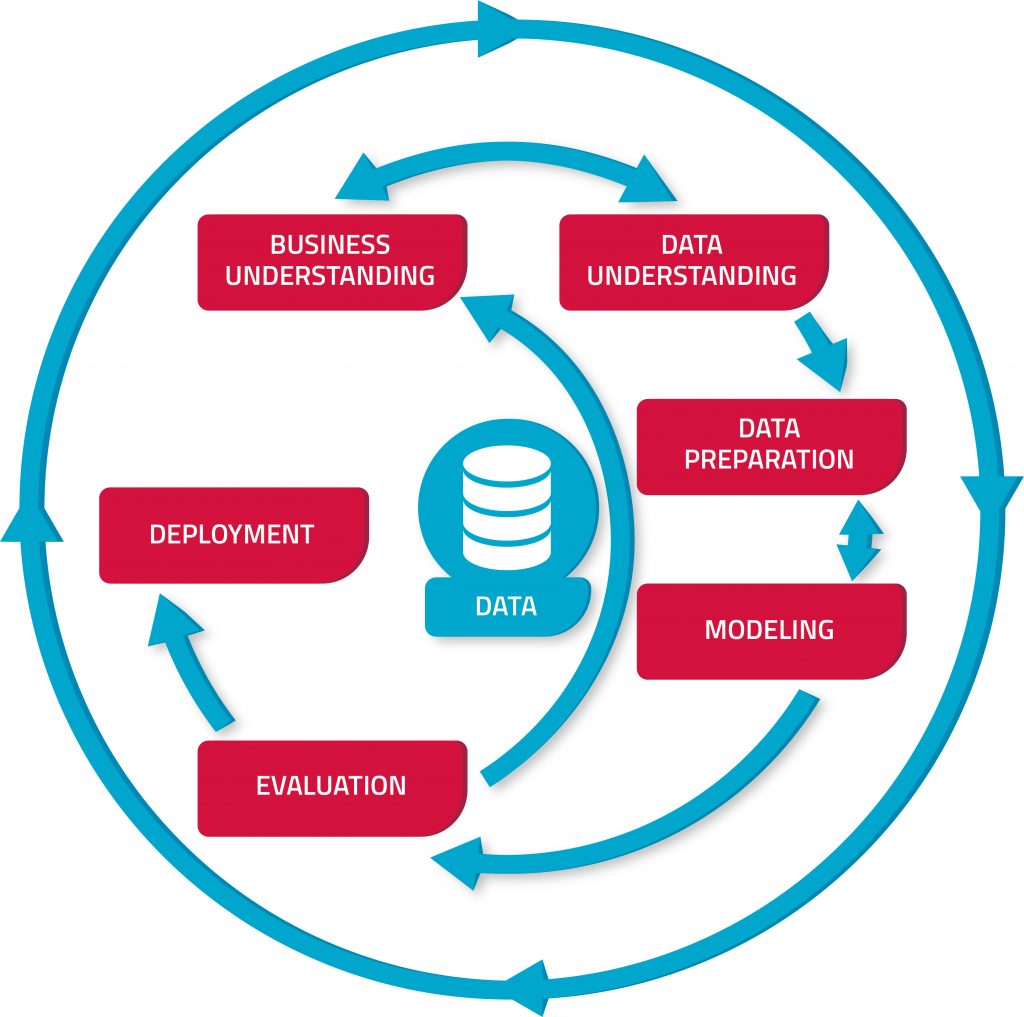
Das sechsphasige Modell hilft dabei, eine standardmäßige Ablaufvorlage bereitzustellen sowie alle relevanten Aspekte im KI-Projekt zu berücksichtigen. Die einzelnen Phasen nennen sich Business Understanding, Data Understanding, Data Preparation, Modeling, Evaluation und Deployment.3

Die erste Phase des Prozesses ist das Business Understanding (deutsch: Geschäftsverständnis). Hierbei geht es darum, zunächst einmal zu verstehen, wie das eigene Geschäftsmodell aufgebaut ist und welche Verbesserungen konkret durch KI erreicht werden können. Ziele und Anforderungen sollten von Beginn an klar definiert und formuliert werden sowie durch Messkriterien ergänzt werden, um im Nachhinein bewerten zu können, ob und wie erfolgreich der gesamte CRISP-DM-Prozess war. Als Startpunkt empfiehlt sich eine Selbstabfrage, um dann eine Datenlandkarte zu erstellen, auf der alle bestehenden und benötigten Daten eingetragen werden. So entsteht ein erster Überblick über die Ausgangslage. Relevante Fragen dabei lauten:
- Welche Daten sind für meine eigenen Produkte und Dienstleistungen wichtig?
- Wer ist meine Zielgruppe und welche Daten benötige ich von ihr?
- Welche Rolle spielen Social Media und Internetdaten und wie kann ich diese nutzen?
- Könnten Daten-Partnerschaften mit anderen Unternehmen interessant sein?
Die zweite Phase nennt sich Data Understanding (Datenverständnis). Hierbei werden die auf der Datenlandkarte erfassten Daten eingesammelt und auf ihre Qualität und Zugänglichkeit hin überprüft. Du weißt noch nicht genau, welche Datenquellen für dich relevant sein könnten? In Abbildung 3 findest du eine Übersicht einiger nützlicher Unternehmensdaten.

Häufig sind die Unternehmensdaten dezentral gespeichert, was die Verarbeitung verkompliziert, da die Daten erst über mehrere Mitarbeiter hinweg gesammelt werden müssen. Sind diese Daten in unterschiedlichen Formaten vorhanden und weisen eine heterogene Struktur auf, sollten harte Filterkriterien und eine klare Datenstruktur genutzt werden, um kein Datenchaos zu erzeugen.3
Interne Daten sind meist relevanter als extern zugekaufte Daten. Allerdings kann auch ein Datenzukauf von Drittparteien Sinn machen, wenn die interne Datenausstattung nicht ausreichend ist. Besondere Beachtung sollten Social-Media-Daten finden, da diese mit Hilfe von Google Analytics4 abgerufen und ausgewertet werden können. Das kann wertvolle Zielgruppeninformation liefern, die dazu beitragen, Produkte und Kundenprozesse zu optimieren.
Die dritte Phase nennt sich Data Preparation und beschreibt die Datenaufbereitung und -bereinigung sowie die Zusammenführung unterschiedlicher Datensätze. Um diese auswertbar zu machen und deren Qualität sicherzustellen, bietet sich der sogenannte ETL-Prozess an.
Die Abkürzung ETL steht für Extract, Transform, Load (deutsch: Extrahieren, Transformieren, Laden) und beschreibt die Umwandlung von Datenstücken in einen Datensatz, der von Algorithmen genutzt und verarbeitet werden kann.
Nach der Zusammenführung der Daten wird der Datensatz in einem zweiten Schritt überprüft und von Duplikaten, Ausreißern oder fehlerhaften Daten befreit. Schließlich werden noch bestehende Datenlücken ergänzt.
Die vierte Phase ist das Modeling (deutsch: Modellierung) und bildet den Kern eines jeden datenbasierten Projekts. Dieser Schritt liefert die wertvollen Ergebnisse und Erkenntnisse, die notwendig sind, um die Projektziele zu erfüllen. Das ist zwar der glamouröse Teil des Projekts, aber auch der zeitlich kürzeste, denn wenn alle vorherigen Schritte korrekt ausgeführt worden sind, gibt es nur wenig Anpassungsbedarf.
Für den Fall, dass die Ergebnisse noch Optimierungspotenzial aufweisen, wird die Methodik so eingestellt, dass der Fokus noch einmal auf der Datenaufbereitung liegt, um so die verfügbaren Daten zu verbessern. Natürliches existieren mehrere Modellierungsformen, die je nach Anwendungsgebiet ihre Vorteile haben. Hier hilft nur Ausprobieren!
Die fünfte Phase nennt sich Evaluation und bewertet, ob die Ergebnisse der Datenanalyse im Einklang mit dem vorher gesetzten Ziel stehen. Sollte keine Übereinstimmung bestehen, startet die Prozess-Schleife von vorne und die Datenbasis muss erneut überprüft, optimiert oder sogar ergänzt werden.
In der letzten und sechsten Phase des Prozesses geht um das Deployment (deutsch: Bereitstellung). Hier werden die abgeleiteten Ergebnisse so aufbereitet, dass die Entscheider bzw. die Endnutzer direkt damit arbeiten können oder eine strategische Entscheidung getroffen werden kann. Oftmals wird dazu ein Report erstellt. Anschließend kann das Data-Mining-Modell fest in die Prozesse des Unternehmens integriert und auf aktualisierte Daten angewandt werden.
Wichtig hierbei: Die sechs CRISP-DM-Phasen müssen nicht streng nacheinander abgearbeitet werden, der ganze Prozess besitzt einen zyklischen Aufbau. Das ermöglicht permanente Sprünge zwischen den einzelnen Phasen. Sämtliche Prozesse sollten dennoch regelmäßig dokumentiert werden. Eine klare Definition des jeweils zu lösenden Problems sowie ein exakter Zuschnitt auf den individuellen Business Case vereinfachen den Prozessablauf.
Natürlich haben Unternehmen, die datenbasiert Entscheidungen treffen wollen, zunächst eine Vielzahl von Herausforderungen zu bewältigen. Gerade am Anfang kann es sehr viel Mühe und Zeit kosten, den internen Datenfriedhof umzugraben.
Allerdings wird sich diese Entscheidung langfristig in Form eines Wettbewerbsvorteils auszahlen, da:
1. strategisch bessere Entscheidungen getroffen werden,
2. das Feedback der Kunden besser umgesetzt werden kann,
3. ein „Daten-Fundament“ und eine digitale Infrastruktur geschaffen werden, die sich für zukünftige KI-Projekte nutzen lassen.
Zum Schluss noch einige Praxis-Tipps für die Anwendung:
- Wenn der CRISP-DM-Prozess ins Stocken gerät, kann es hilfreich sein, die Zieldefinition zu überprüfen und möglicherweise den Anwendungsfall zu verkleinern.
- Daten miteinander kombinieren, um bessere Aussagen zu bekommen.
- Frei zugängliche Datenquellen nutzen oder Daten zukaufen.
- Nur wirklich relevante Daten nutzen, um Prozesse nicht unnötig aufzublähen.
- Eine verständliche und gründliche Datenaufbereitung ist das A und O.
Teile der Zitierungen dieses Blogs wurden mit der maschinellen Übersetzungs-Software DeepL übersetzt.
Genutzte Quellen:
(1) https://www.bigdata-insider.de/was-ist-data-mining-a-593421/
(2) CRISP-DM. (2019). CRISP-DM methodology. http://crisp-dm.eu/home/ crisp-dm-methodology/. Letzter Zugriff: 21.09.2020.
(3) Quick Guide KI-Projekte – Einfach machen, Verena Fink, 2020, Springer Gabler
(4) https://www.youtube.com/watch?v=Gxub4_dnIWE&t=32s
Autor: Bernhard Trojca, Content-Manager HubWerk01:KI



